Azure AD is a distributed computing system which means, all of the data must be duplicated to the various data centers. You can read about the architecture of Azure here. We occasionally see a case where a customer is using Microsoft Graph to programmatically create a user, group, application, etc. and getting the object id back from that request and then using that id to do some kind of management task ( GET, PATCH, etc…) sometimes in the same application or a different application. But instead of a success response, the application gets a 404 ( not found ) for that id. What gives? Simply put, you hit one node in Azure to create the object but because of things like gateways and load balancers, the PATCH request went to a different node where the id did not yet exist. This was because of a replication delay for the change to be propagated across all of the nodes in a distributed system. This concept is called “Eventual Consistency” which means, eventually, everything will be consistent throughout all of Azure — just not instantly. You can read this “fun” article about eventual consistency and why Azure is an eventually consistent system here.
So, using this scenario where an application has created a user in Azure using Microsoft Graph and then tried to update the user but got a 404 response; here is a diagram of that scenario:
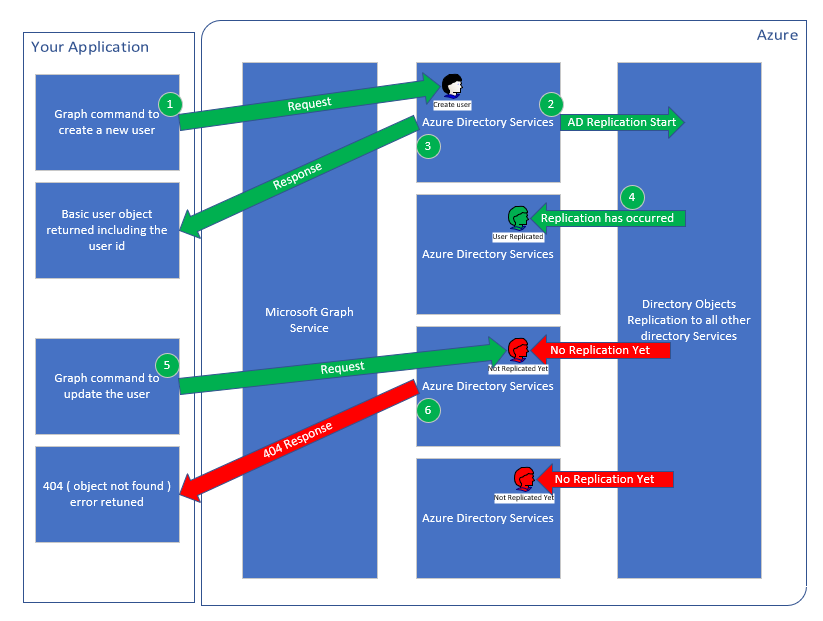
Looking at that diagram, the application made a Microsoft Graph request to create a user in Azure. The service has then started the replication process and returned an object for that user, which will include the id and any data you used in the request for the user. While your application was receiving that data, the replication process has updated one replica ( this diagram does not accurately represent the number of replicas / full architecture of Azure ) but now your application is going to perform an update on that user. As a result, a lookup for that id will be made but the connection has hit a replica that is not yet updated with the user object and so a 404 is returned because the user was not found.
So, what do you do about this? The only thing you can do is to wait a bit of time and then try the update request again. You know the object should have been created because you got the success response and the object id back. However, how long you wait is actually up to you. We always recommend implementing some form of a retry operation ( try / catch block statement ) with a a back-off time delay heuristic. Normally, I will tell customers to have the application wait a couple of seconds and then try again and if you get another 404, then double that time and repeat. Replication delay can take minutes to complete. Obviously, this can’t go on forever so at some point, you just have to call it an error. This is the normal procedure in this type of scenario.
In summary, since data like the user object must be replicated to all data centers ( otherwise, how would we know how to log a user in no matter where that user is? ) and we can’t update them all instantaneously, you may occasionally get a 404 error when looking the user up or updating the user. Your application must be aware of this issue and handle the error accordingly with a back-off wait period to give the replication process the time needed to finish the request.